The mixed channel (MC) version embeds different physical channels within the same token. This representation is more computationally efficient and tokens have a higher information density. However, it is less flexible transfer learning applications, because the types of channels need to be known at training time.
Abstract
We introduce PDE-Transformer, an improved transformer-based architecture for surrogate modeling of physics simulations on regular grids. We combine recent architectural improvements of diffusion transformers with adjustments specific for large-scale simulations to yield a more scalable and versatile general-purpose transformer architecture, which can be used as the backbone for building large-scale foundation models in physical sciences.
We demonstrate that our proposed architecture outperforms state-of-the-art transformer architectures for computer vision on a large dataset of 16 different types of PDEs. We propose to embed different physical channels individually as spatio-temporal tokens, which interact via channel-wise self-attention. This helps to maintain a consistent information density of tokens when learning multiple types of PDEs simultaneously.
Our pre-trained models achieve improved performance on several challenging downstream tasks compared to training from scratch and also beat other foundation model architectures for physics simulations.
Architecture
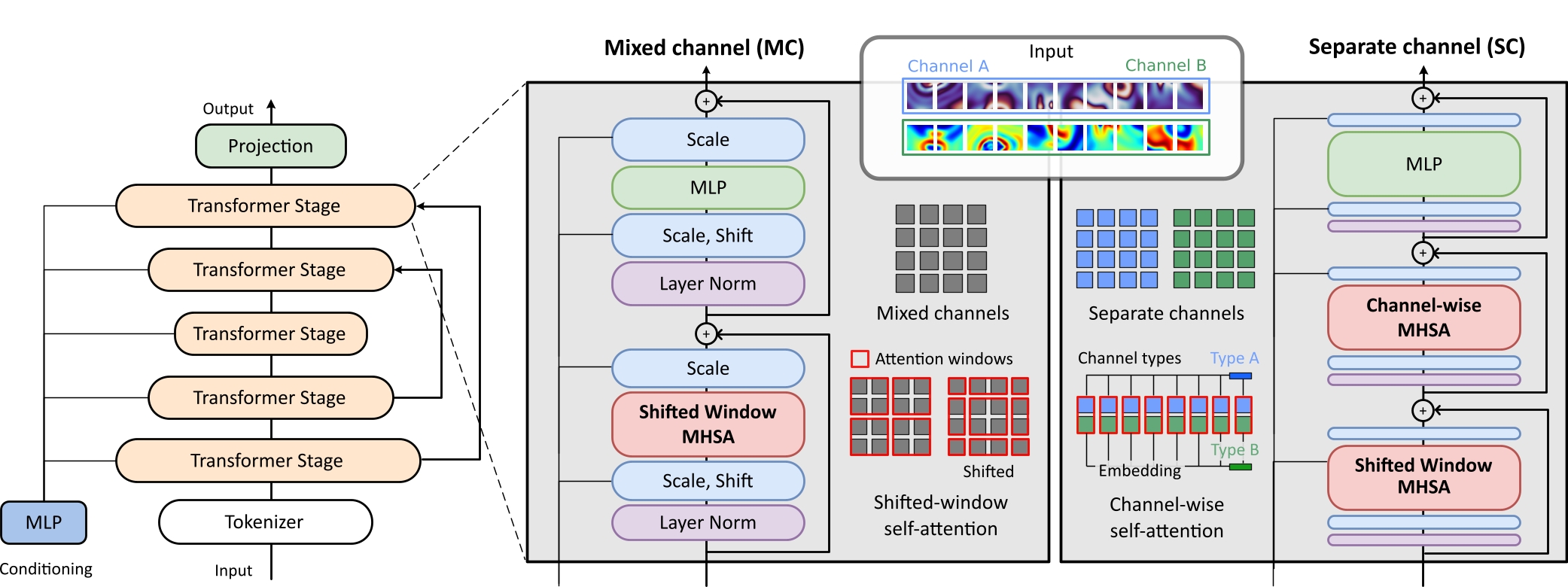
Data consisting of different physical channels is partitioned into patches and embedded into tokens.
The multi-scale architecture combines up- and downsampling of tokens with skip connections between transformer stages of the same resolution.
The attention operation is restricted to a local window of tokens.
The window is shifted between two adjacent transformer blocks.
Conditionings are embedded and used to scale and shift the intermediate token representations.
Mixed Channels
Separate Channels
The separate channel (SC) version embeds different physical channels independently, learning a more disentangled representation. Tokens of different physical channels only interact via axial self-attention over the channel dimension. The types of channel (velocity, density, etc.) are part of the conditioning, which is distinct for each channel
Performance
Comparison to SOTA
We compare PDE-Transformer to state-of-the-art transformer architectures for computer vision on our pretraining dataset of 16 different PDEs, in particular a modern UNet architecture and Diffusion transformers with token up- and downsampling U-DiT. Additionally, we compare to scalable operator transformer scOT and FactFormer, both transformer-based architecture for physics simulations. PDE-Transformer achieves superior performance while requiring less training time compared to other models.
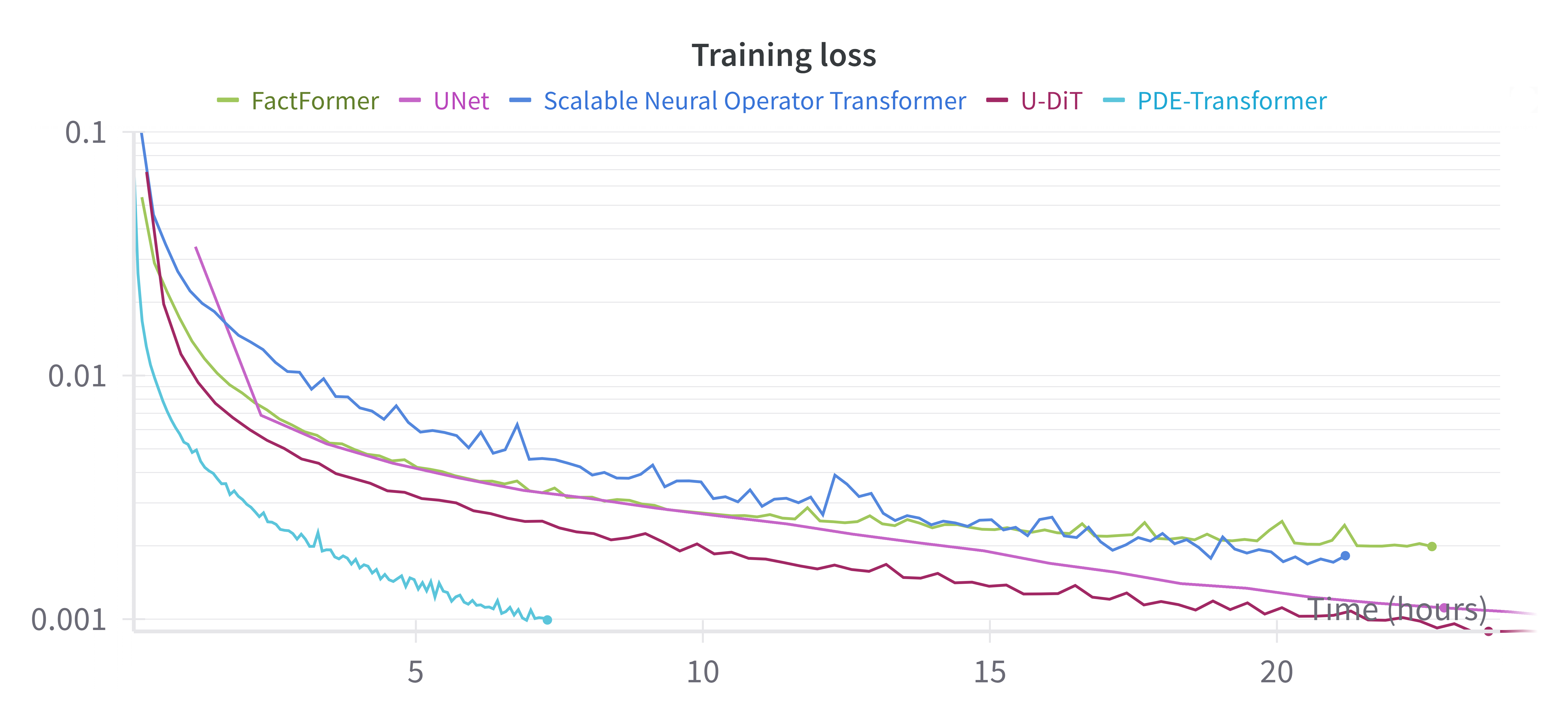
Training time comparison with state-of-the-art models on 4x H100 GPUs.
PDE-Transformer achieves superior performance while requiring less training time compared to other models.
| Architecture | Multi-scale | Scalable | Probabilistic | Non-square Domains | Periodic Boundaries | Advanced Conditioning |
|---|---|---|---|---|---|---|
| FactFormer | ✗ | ✗ | ✗ | ✗ | ✓ optional | ✗ |
| UNet | ✓ | ✗ | ✓ | ✓ | ✗ | ✓ |
| scOT | ✓ | ✓ | ✗ | ✗ | ✓ required | ✗ |
| U-DiT | ✓ | ✗ | ✓ | ✓ | ✗ | ✓ |
| PDE-Transformer | ✓ | ✓ | ✓ | ✓ | ✓ optional | ✓ |
Comparison of capabilities across different architectures. PDE-Transformer combines the advantages of previous approaches while addressing their limitations.
Scaling Effects
Patch size
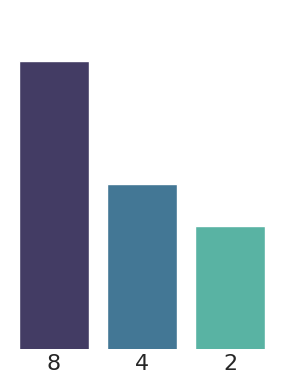
Normalized test RMSE for different patch sizes.
Lower is better.
Lower is better.
The patch size is a key hyperparameter of the model. We find that a patch size of 4x4 works well for all PDEs. Larger patch sizes lead to fewer tokens and thus faster training, but performance may degrade. Smaller patch sizes lead to more tokens, requiring more floating point operations (FLOPs) and memory, but improve performance.
Token embedding dimension
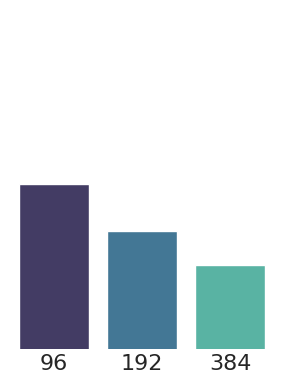
Normalized test RMSE for different token embedding dimensions.
The token embedding dimension is another key hyperparameter. Larger token embedding dimensions lead to a lower information content of tokens and increase the memory footprint as well as the number of FLOPs. The model performance is improved. Smaller token embedding dimensions lead to a lower memory footprint and faster training time, but the model may not be able to learn the PDEs as well.
Finetuning on Downstream Tasks
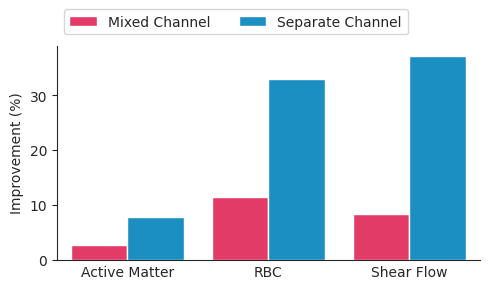
Performance improvements when finetuning on downstream tasks
compared to training from scratch. Higher is better.
compared to training from scratch. Higher is better.
We finetuning the pre-trained PDE-Transformer on different downstream tasks. Specifically, we consider the active matter, Rayleigh-Bénard convection, and shear flow datasets from The Well, which described non-linear phenomena arising in computational biology, fluid dynamics and thermodynamics.
The selected datasets have setups for periodic and non-periodic boundary conditions, non-square domains, different physical channels and high resolutions of up to 512x256, demonstrating the capabilities of PDE-Transformer.
We find that finetuning a pre-trained PDE-Transformer on these tasks improves the performance compared to training from scratch. Importantly, finetuning is more efficient for the separate channel version, which learns a more disentangled representation of the physical channels.

Shear flow simulation, see The Well. Predicted density.
BibTeX
@article{holzschuh2025pde,
author = {Holzschuh, Benjamin and Liu, Qiang and Kohl, Georg and Thuerey, Nils},
title = {PDE-Transformer: Efficient and Versatile Transformers for Physics Simulations},
booktitle = {Forty-second International Conference on Machine Learning, {ICML} 2025, Vancouver, Canada, July 13-19, 2025},
year = {2025}
}